機械学習と木材ビジネスの展望BLOG DETAIL
最近耳にすることの多い「機械学習(マシンラーニング)」や「深層学習(ディープラーニング)」。ここ最近メディアを賑わせているChatGPTにはじまり、翻訳サイト、スパムメールの振り分け、顔認証、音声認識、画像処理などに利用されるなど、我々を取り巻く生活にもはや欠かせない技術となっています。
人類を取り巻く産業の中で、最も古い歴史を持つ木材ビジネスもその例に漏れず、昨今では木材事業や林業と機械学習を結び付ける取り組みが多く模索されつつある状況です。今回は、そんな機械学習技術の要点と、木材ビジネスへの活用について解説をおこなっていきます。
関連記事「ブロックチェーンが木材流通業界を変える!?意外な関係性について」
機械学習の基礎理解
機械学習と一般的に呼ばれているモデルを分類すると、以下の3つにわけることができます。「機械」ではなく「機械学習」と呼ばれるのは、要するに電卓のような単なるデータの出力ではなく、過去のデータを元に学習し、将来の予測結果を改善するという動的な要素をもった動きを持つからです(この点、過去の経験を元に自身のスキルを向上させていく人間と近いのではないでしょうか)。
- 教師有り学習
- 教師無し学習
- 強化学習
教師有り学習は、上記の中では今までの統計学の領域と一番近しいという認識ではないでしょうか。説明変数を用いて目的変数を予測する、といった方法で、決定木、ランダムフォレスト、回帰分析などを用いて過去データから数式を作り、将来の傾向を予測します。天候、株価、給与モデル、など、が教師有り学習の最たる例といえます。インプットをおこなうのは人間で、なにが正しい出力かを教えるのも人間のため、AIを人間に例えるなら、幼稚園児くらいのニュアンスでしょうか。
教師無し学習は、特に答えとなる目的変数の無い状態から、AIがクラスタリング(つまり、カテゴリ化)をおこない、傾向を予想する、といった手法です。例えばコンビニを利用する10000人のデータ(購入履歴)を入力し、そこからグループ化をおこなってもらうような場合は教師無し学習に当てはまります。
強化学習は、この中では一番近未来感が強い、つまり機械が自身の行動を元に自動でデータを蓄積し、その蓄積を元に出力の改善をおこなっていくものです。囲碁や将棋のAIでの最善手の探求、お掃除ロボットや自動運転などがこの例として挙げられています。もっとも、強化学習単体で機能するというよりも、元となるデータを教師有り学習で入力し、そこを起点にモデルを強化していく、という手法がとられることが多いと言えるでしょう。
機械学習(カテゴリ判定)の具体例
機械学習手法を用いた代表的かつ簡易な例としては、「アヤメの識別」が挙げられます。出典はイギリスの統計学者で生物学者のロナルド・フィッシャーが1936年に発表した「The use of multiple measurements in taxonomic problems」の論文で、80年以上前のものであるにも関わらず、線形判別分析の古典教本として今でも利用されています。
どんな内容かというと、3種類のアヤメ(Iris setosa,Iris virginica,Iris versicolor)と、それぞれに対して50のサンプル、それらに対する「がく片の長さ」「花弁の長さ」「がく片の幅」「花弁の幅」の4つの説明変数をもって、それらのサンプルがどのアヤメの種類に属するかを識別する手法です。
K近傍法を用いる場合、過去の説明変数データから、以下のような「クラスター」を分類し、入力した数値に近いクラスターが機械的に「アヤメの種類」として判定されます。最もこの手法、100%の精度でおこなわれるわけではなく、入力方法いかんによっては以下の図のように乖離が発生します。
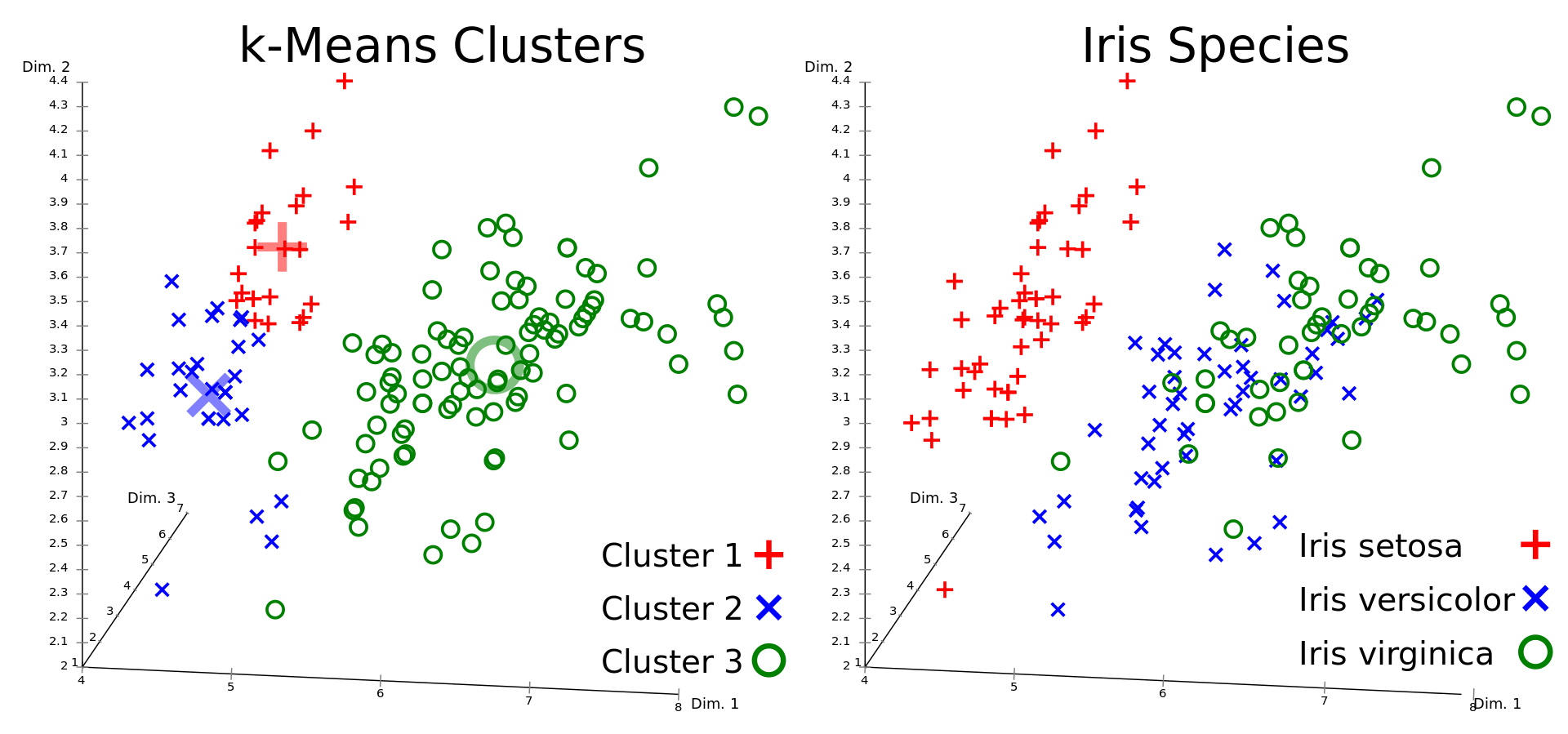
(クラスターが混合するので、この場合では教師有り学習が推奨される 引用元:Wikipedia)
80年以上前の論文ですが、そのシンプルさからプログラミング言語におけるテストモデルとしても用いられやすく、RやPythonといった言語ではではあらかじめデータセットが用意されています。
機械学習と木材ビジネス
さて、ここまでの解説を通じて、何か「機械学習と木材ビジネス」、という繋がりでつかめてくるものがないでしょうか?すでに企業や団体に取り入れられている技術、あるいは研究の進んでいる分野の例としては以下のようなものが挙げられます。
- 森林の衛星写真から特定範囲の樹種の判定をおこなう
- ミクロレベルでの樹種判定
- 木材の曲げ特性、ゆがみの将来予測
- 断面図やCTを用いた木材強度や耐水性、耐腐性の判定
- 節などによる木材グレードの判定
機械学習の得意領分は、膨大な過去のデータによって裏打ちされた、文字通り正確無比、迅速かつ膨大な量の判定が下せることです。そのため、工場に流れてくる膨大な量の木材をスキャンさせ、グレードごとにカテゴライズしたり特定の用途別に識別するなど、特に大量生産・大量識別方式においては絶大なアドバンテージを誇ります。
また、木材の表面写真だけではなく、CTなどと組み合わせることで、含水量などのデータから、将来的なゆがみ率、曲がり率、といった木材建築にとって重要な数値の推測をおこなうことも可能です。過去の経験による木材の質の「見極め」は、今まで熟練した職人の十八番とされていたスキルですが、何千、何万といった写真データをインプットしたAIは、こういった絶妙な判断を必要とする領域においてすでに人間を凌駕しつつあります。
機械は人間を超えるか?
人類と木材資源との関係は数千年前、まさに人類の文明化とともに始まりました。その伝統的な関係性が、ここ数年の技術革新によって劇的に変化しようとしています。それでは、今後職人芸、伝統芸、とされていた木材関係の技術やスキルは、次第にAIにとって代わられていくのでしょうか?
さて、ここから先はあくまで個人的な感想ですが、我々人間の得意とする分野と、AIの得意とする領域には、まだ乖離があるように思え、いくつかの要因から、少なくとも向こう20~30年は、木工に携わる人の技術やスキルが完全に機械にとって代わられることはないように思われます。
(※以下、あくまで個人的見解です)
理由として、まず、こうした機械学習を応用した技術の実現には(機械学習全体に言えることですが)「膨大かつ良質な元データ」が必要になる、という重要な点を忘れてはいけません。少なくとも2023年時点において、AIは与えられたデータを元に将来の予測をしたり、人間の目視よりも早く正確なクオリティ判断をこなすことが可能になっていますが、そのAIの教育には人間による元データ(画像や統計データ)のインプットが条件づけられています。「工場などで流れてくる膨大な量の木材を直接目視によって識別する」ようなスキルの需要は減るかもしれませんが、その代わりに機械にデータをインプット、特定の条件をフィルタリングするための新たな需要が生まれることでしょう。

機械学習の元となる木材データは現場にのみ存在する
続いて、機械学習によってもたらされる「最善手の判定」や「識別」は、多くの量を短時間で捌かなくてはいけない汎用品や大量生産の分野においては優秀であっても、手作業やユニーク性が問われる分野においてはあまり量的メリットを生まない点です。例えば、木片のデータから「最適な木片の使い方」を算定してくれるアプリが登場したとしましょう。判定はGoogleなどの大企業の集めた過去の膨大なデータの蓄積に基づいておこなわれるため、同じ大きさ、幅、重さの木片をインプットすれば毎回同じ答え(「コノ木片ハ、椅子二使うウト良イデショウ」)が返ってきます。ユニーク性や一点物であることを売りにする職人がみな同じ結果をあてにし始めると、市井に出回る製品は同じようなデザインになってしまい、結局みながみな同じ嗜好を持つつまらない世の中になってしまうのではないでしょうか。対して、個々の工場や職人がAIに対して強化学習をするには集められるサンプル数が少なすぎるため、やはり効率的ではないでしょう。

機械に「判別」はおこなえても、独創性や手作業は人間の本分
最後に、機械学習によってもたらされるアウトプットはあくまで、過去のデータの延長である、という点が挙げられます。例えば、自身の個人情報を入力したら自身の嗜好や健康状態、資金状態から「自身に適した木材家具」を自動でおススメしてくれるアプリが登場したとしましょう。こうしたアプリの限界点は、あくまで膨大な統計(満足度など)によって推測される個人へのマッチであって、過去のデータの蓄積と確率論の枠を出るものではありません。つまり、人類の進歩、新しいフォルムや独創性に寄与することがないわけです。こういった分野においては、やはりスーパーコンピューターを凌駕する人間の脳の「独創性」がまだまだ物をいうのではないでしょうか。
とどのつまり、機械は人間同様、過去のデータや経験によって「将来を予想する」ことが可能になりましたが、ここから「過去のデータの延長でない」、すなわちお手本帳に載っていない道を切り開いていくのは、やはりいつの世も機械ではなく人間の本分なのではと思います。一方で、グレードの識別や樹種の判定など、機械の得意とする分野に関しては共存する姿勢も必要でしょう。

大川職人の手によって現代に蘇る黄金の茶室
我々プロセス井口は、間断なく伝統と革新を融合させ、新たな木材史を切り開いていく所存です!
